
Choosing the right AI training data is crucial if you are to have a successful application. So why does no talk about the essential process of data engineering?
Artificial Intelligence (AI) is probably one of the most used and strongest buzz words out there today. You say you are building an AI application, and it gets your friends’, family’s, and your investors’ attention immediately.
Today, AI is thought of as a magic box. “If a problem cannot be solved any other way or is too difficult to tackle, using AI will solve it.” This is a misconception a lot of us have today.
We expect way too much of AI and it is not entirely our fault. J.A.R.V.I.S. in Iron Man and Skynet in The Terminator might have influenced our thinking on AI.
In the real world, prototype and proof-of-concept projects fool us into thinking we are on our way to life in a Marvel comic, but when we try to scale to production, instead we get a tragedy.
I’m sure you’ve seen this meme countless times.

As an AI engineer myself, this meme looks about right to me. The first time I stumbled upon this, I couldn’t stop laughing, not because it was funny, but because it was soo relatable. (I’d love for you to share your story if you share this feeling. Post a comment and join the conversation).
But why is that? Why do we hear huge promises made in favor of AI but then fail to see it in action?
After five years in this field, my opinion is that this boils down to one simple reason: You are using the wrong data.
Finding and Using Relevant AI Training Data
During the learning phase, the AI is shown examples of input and its corresponding output. By looking at these examples, it learns patterns and relationships between them. After the learning phase is over, it is given new input, and based on its knowledge, it makes a prediction.
The type of AI that has shown great results in academia is called deep learning. And we all know that we need a huge amount of data for it.
Up until this point, you might have guessed how critical DATA is for the success of AI.
In practice, somehow, we tend to grab whatever data we can get our hands on quickly, train and keep fine-tuning the AI, and then wonder “Why is my model not accurate enough?”. When we know that DATA is so critical to the success of our application, why are we rushing through it? We focus all our attention on AI and not the thing that supports it – Why?
Data engineering is as important as the magic box itself. Without it, there is no magic. All you get is failed tricks.
Let’s talk about data engineering. After we define what we want the AI to do, data engineering is the next step. It includes defining data, collecting data, cleaning data, and labeling. These are required steps before we can train an AI.
Let’s dig into each of the steps in data engineering.
Step 1: Defining Data
As with any other software, we need to first define the input and expected output. If you are looking to build a cat vs dog classifier, then the input will be an image and the output will be a label, either “Dog” or “Cat.”

That’s intuitive enough for anyone to figure out. You would collect thousands of images of cats and label them as “Cat” and thousands of images of dogs and label them as “Dog” and then use this data to train the cat vs dog classifier.
This is what most AI engineers do today during the initial proof-of-concept phase of an AI project, and it has worked well so far.
But what happens when the project goes beyond the proof-of-concept phase?
In most cases, the failure rate of the AI starts to increase. In the cat vs dog example, it will start misclassifying the images more often.
Why?
Because there is a huge difference between the images the AI was trained on and the images the AI is now seeing.
Imagine you are building a dog detector. You have different applications where it will be used; one in the home security camera, and the other on your phone.
You define images of dogs to be input data and bounding box coordinates of the dog as output data. Then you collect as many images with dogs as possible, label them, and train a dog detector AI.
Then you use the dog detector in the applications. Will the accuracy be the same for both applications?
The answer is maybe, but most probably NO.
The AI on your phone sees a different variety of images compared to the AI on your home security camera. What was the AI trained on? Any image with a dog in it and that is the issue.
So this is what we should do instead.
Take a step back and understand the application better.
The first question to ask here is, “Where will this be used?” Your answer might be “I want this on my home cam, so it can notify me when it sees my dog is near the garden area”, or “I want this on my mobile phone, so I can take pictures of dogs and it tells me all about it.”
In both cases, you are building a dog detector. My question to you is, are the images you are going to collect to train a dog detector for both these scenarios going to be the same, somewhat similar, or completely different?
If your answer is “That’s a tricky question” then you are on the right track.
What’s often overlooked when defining the training data are the important details of the application; where it will be used, how far away the object of interest will be, how big the object of interest is, the orientation, the angle, etc.
The way I see it, to start with, you can use the same set of images to train the initial dog detector model for both scenarios. At this point, MobilePhone-DogDetector v1 and HomeCam-DogDetector v1 are the same.
But eventually, you want to collect specific examples for each case separately and keep fine-tuning it on more specific examples. For MobilePhone-DogDetector, you want to collect more examples of images taken from your smartphone and your friends’ smartphones, which might be a close-up image. And for HomeCam-DogDetector, you want to collect images of your dog taken from your home security camera, which might be further away.
Now, you have DogDetector v2 and HomeCam-DogDetector v2 and these are fine-tuned so they work best for their specific scenario.
This concept is known as Adaptive Radiation™ and was first introduced by AI thought leader Dr. Shivy Yohanandan, the co-founder of Xailient.
Yohanandan, a neuroscientist and PhD in AI, helped build the first bionic eye. After years of research, he figured out the mechanism behind how humans and animals see efficiently and accurately and is now teaching computers to see as we do. Dr. Shivy Yohanandan says:
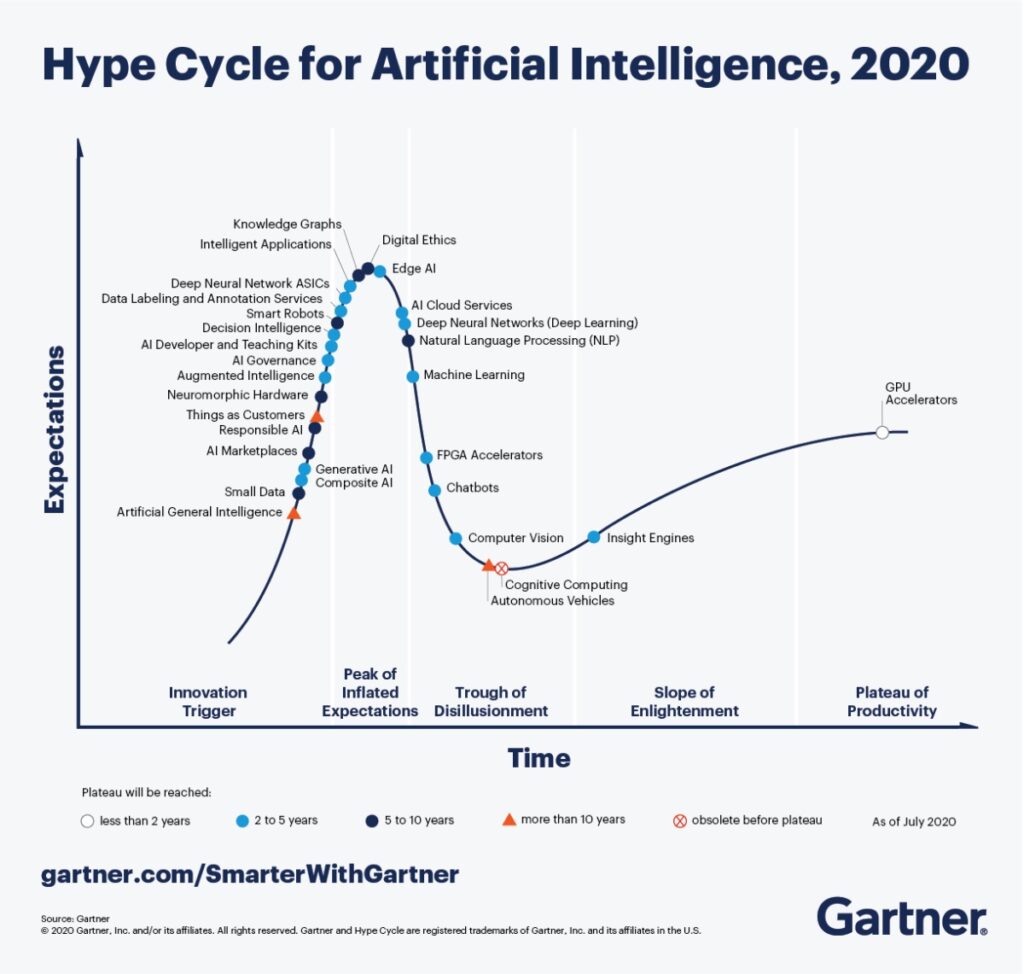
“This idea of generic one-model-to-rule-them-all AI is a dead-end with the current state-of-the-art deep learning architectures. Either we need some revolutionary paradigm-shifting advances in deep learning to achieve better model generality, or we need to figure out a better way using the existing state-of-the-art (like our nature-inspired Adaptive Radiation solution). Even the Gartner hype cycle shows that the computer vision hype has plummeted, and I strongly believe this is because people (especially in industry and real-world applications) are accepting the real limitations of generic computer vision models like YOLOs and SSDs.”
The bottom line is that training data must be as close to the environment where the AI is intended to be used as possible. You can use general data to start training your AI, but eventually, if you want good accuracy, you need to fine-tune your AI with examples as close to the use-case’s environment as possible.
Step 2: Collecting Data
After you define the type of data that you want to collect, start collecting data manually or programmatically. For instance, for the HomeCamera-DogDetector, you can record video clips day and night for a week and then outsource someone to extract frames with dogs in them.
Step 3: Cleaning Data

After you have collected data, it is important to go through a sample to get a sense of how good the data is. Is the image clear enough? Or is it a motion blur? Are you able to visually see a dog in the image? Is there a good variety of images? For example, for the HomeCamera-DogDetector, are there images with the dog always around the center of the image, or are there images with the dog closer to the edges as well?
Only once you’ve gone through it, will you have a clear direction as to whether you should proceed with data labeling and training, collect more data, or make adjustments to the data collection process itself.
Through the data cleaning process, you need to make sure your dataset is a good representation of what you expect the AI to see and under what circumstances it is expected to work when it is deployed.
Step 4: Data Labeling

Labeled data is what needs to be fed into the AI during the training phase. Data labeling is where, given an input image, you say what the expected output of that image is, so the AI can learn from it.
To summarise, training on the relevant data is critical and has a big role in any successful AI application. The training data must be as close to the input data that the AI is expected to see (e.g. lighting, angle, distance, orientation, etc.) to the point where you’re training one AI model per camera! Data collection, data cleaning, and data labeling are other important steps of data engineering.
Looking to implement real-time face detection on a Raspberry Pi? Check out this post.
About the Author
