
Many real-world applications demand real-time, Edge AI processing capabilities. Given this need, model compression will become increasingly important.
Whether you’re new to computer vision or an expert, you’ve probably heard about AlexNet winning the ImageNet challenge in 2012. That was the turning point in computer vision history because it showed that deep learning models can perform tasks that were considered very difficult for computers, with an unprecedented level of accuracy.
But did you know that AlexNet had 62 million trainable parameters?
Interesting right.
Another popular model VGGNet which came out in 2014 had even more – 138 million trainable parameters.
That’s more than twice that of AlexNet.
You might be thinking… I know that the deeper the model is, the better it will perform. So why are you highlighting the number of parameters? It is obvious that the deeper the network is the more parameters there will be.
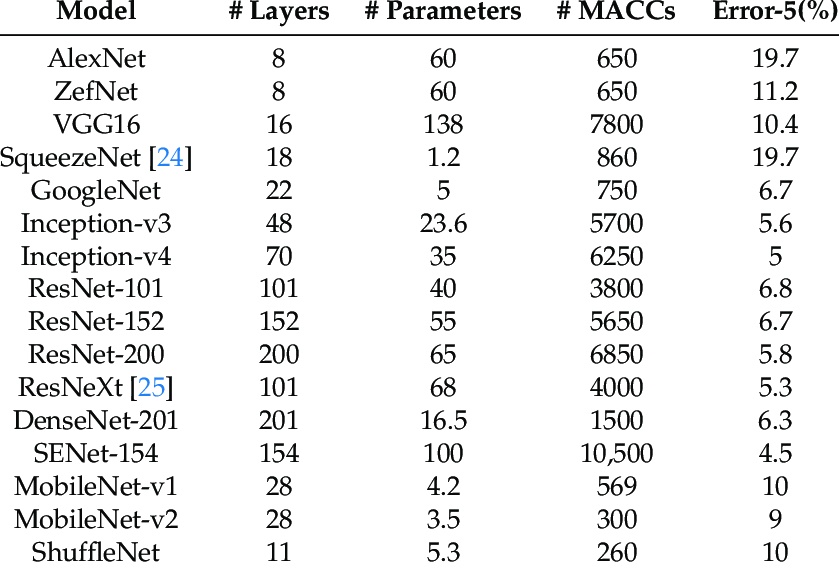
Sure, these deep models have been benchmarks in the computer vision industry. But when you want to create a real-world Edge AI application, would you choose these models?
I guess the real question we should ask here is: CAN YOU USE THESE MODELS IN YOUR APPLICATION?
Hold that thought for just a minute!
Let me divert here for a bit before I get to the answer. (But feel free to skip to the end.)
The IoT and Demand for Real-Time Processing
The number of IoT devices is expected to reach 125–500 billion by 2030, and assuming that 20% of them will have cameras, IoT devices with cameras will be a 13–100 billion unit market.
IoT camera devices include home security cameras (such as Amazon Ring and Google Nest) that open the door when you reach home or notify you if it sees an unknown person, cameras on smart vehicles that assist your driving, or cameras at a parking lot that open the gate when you enter or exit, just to name a few! Some of these IoT devices are already using Edge AI to some extent and others are catching up slowly.

Many real-world applications demand real-time, Edge AI processing capabilities. A self-driving car is a perfect example of this. In order for cars to drive down any road safely, they must observe the road in real-time and stop if a person walks in front of the car. In such a case, processing visual information and making a decision needs to be done in real-time, on-device.
So, returning to the earlier question: CAN YOU USE THESE MODELS IN YOUR APPLICATION?
If you’re using computer vision, there’s a high chance your application requires an IoT device, and looking at the forecast for the IoT devices, you’re in good company.
The main challenge is that IoT devices are resource-constrained; they have limited memory and low computing power. The more trainable parameters are in a model, the bigger its size. The inference time of a deep learning model increases along with the increase in the number of trainable parameters.
Moreover, models with high parameters require more energy and space in comparison to a smaller network with fewer parameters. The end result is that when the size of the model is big, it’s difficult to deploy on resource-constrained devices. While these models have been successful in achieving great results in a lab, they aren’t usable in many real-world applications.
In the lab, you have expensive and high-speed GPUs to get this level of performance, but when you deploy in the real world, the cost, power, heat, and other issues preclude the “just throw more iron at it” strategy.
Deploying deep learning models on the cloud is an option as it can provide high computational and storage availability. However, it will have poor response times due to network latency, which is unacceptable in many real-time applications (and don’t get me started on the network connectivity’s impact on overall reliability, or privacy!).
In short, AI needs to process close to the data source, preferably on the IoT device itself!
This amalgamation of Edge processing and AI is known as Edge AI.
It leaves us with one option: Reducing the model size.
How Do We Practice Model Compression on Edge Devices?
Practicing model compression to make a smaller model that can run under the constraints of Edge devices is a key challenge. And that too without compromising on accuracy. It is just not enough to have a small model that can run on resource-constrained devices. It should perform well, both in terms of accuracy and inference speed.
So how do you fit these models on limited devices? How do you make them usable in real-world applications?
Here are a few techniques that can be used to reduce the model size so that you can deploy Edge AI on your IoT device.
Pruning
Pruning reduces the number of parameters by removing redundant, unimportant connections that are not sensitive to performance. This not only helps reduce the overall model size but also saves computation time and energy.
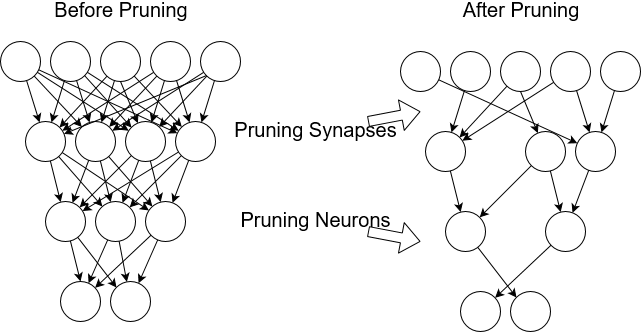
Pros:
- Can be applied during or after training.
- Can improve the inference time/ model size vs accuracy tradeoff for a given architecture
- Can be applied to both convolutional and fully connected layers
Cons:
- Generally, does not help as much as switching to a better architecture
- Implementations that benefit latency are rare as TensorFlows only bring model size benefits
Quantization
In DNN, weights are stored as 32-bit floating-point numbers. Quantization is the idea of representing these weights by reducing the number of bits. The weights can be quantized to 16-bit, 8-bit, 4-bit, or even with 1-bit. By reducing the number of bits used, the size of the deep neural network can be significantly reduced.
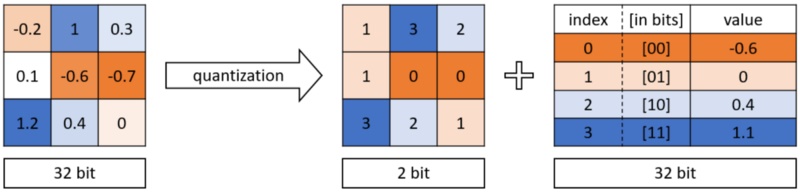
Pros:
- Quantization can be applied both during and after training
- Can be applied to both convolutional and fully connected layers
Cons:
- Quantized weights make neural networks harder to converge. A smaller learning rate is needed to ensure the network will have good performance. [13]
- Quantized weights make back-propagation infeasible since gradient cannot back-propagate through discrete neurons. Approximation methods are needed to estimate the gradients of the loss function with respect to the input of the discrete neurons [13]
- TensorFlow’s quantize-aware training does not do any quantization during the training itself. Only statistics are gathered during training and those are used to quantize post-training. So I am not sure if the above points should be included as cons
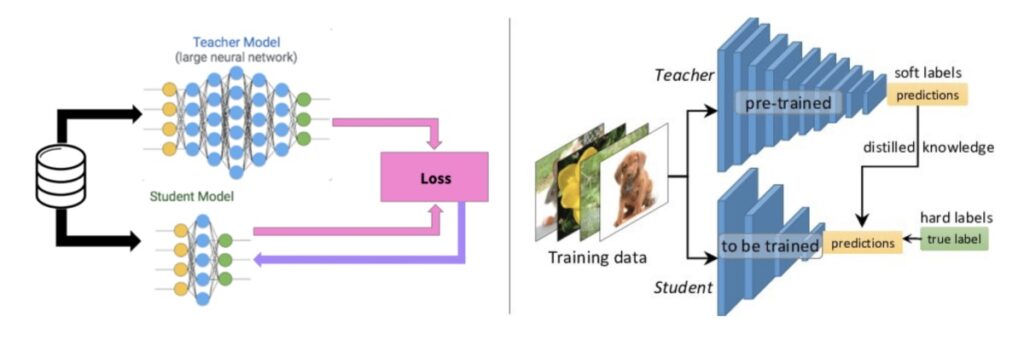
Knowledge Distillation
In knowledge distillation, a large, complex model is trained on a large dataset. When this large model can generalize and perform well on unseen data, it is transferred to a smaller network. The larger model is also known as the teacher model and the smaller network is also known as the student network.
Selective Attention
Selective attention is the idea of focusing only on objects or elements of interest while discarding the others (often background or other task-irrelevant objects). This method of model compression is inspired by the biology of the human eye. When we look at something, we only focus on one or a few objects at a time, and other regions are blurred out.

This requires adding a selective attention network upstream of your existing AI system or using it by itself if it serves your purpose. It depends on the problem you are trying to solve.
Pros:
- Faster inference
- Smaller model (e.g. a face detector and cropper that’s only 44 KB!)
- Accuracy gain (by focusing downstream AI on only the regions/objects of interest)
Cons:
- Only supports training from scratch
Low-Rank Factorization
Uses matrix/tensor decomposition to estimate the informative parameters. A weight matrix A with m x n dimension and having a rank r is replaced by smaller dimension matrices. This technique helps by factorizing a large matrix into smaller matrices.
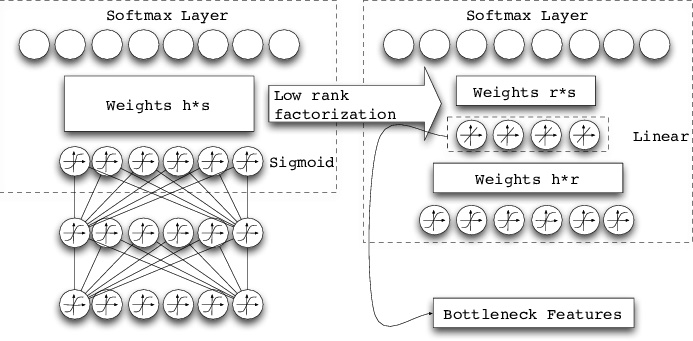
Pros:
- Can be applied during or after training
- Can be applied to both convolutional and fully connected layers
- When applied during training, can reduce training time
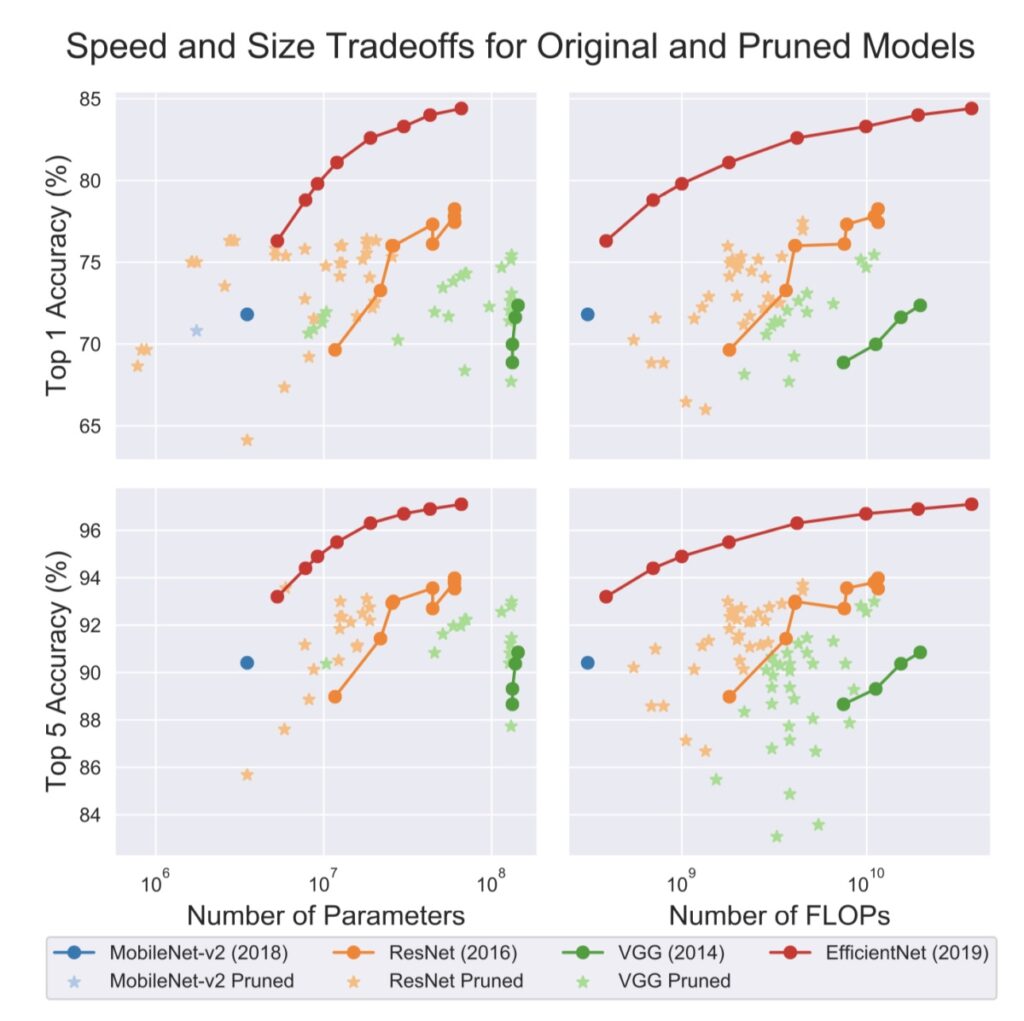
The best part is, all of the above techniques are complementary to each other. They can be applied as-is or combined with one or multiple techniques. By using a three-stage pipeline; pruning, quantization, and Huffman coding to reduce the size of the pre-trained model, the VGG16 model trained on the ImageNet dataset was reduced from 550 to 11.3 MB.
Most of the techniques discussed above can be applied to pre-trained models as a post-processing step to reduce your model size and increase inference speed. But they can be applied during training time as well. Quantization is gaining popularity and has now been baked into machine learning frameworks. We can expect pruning to be baked into popular frameworks very soon.
In this article, we looked at the motivation for deploying deep-learning-based Edge AI models to resource-constrained devices such as IoT devices and the need to reduce model size so they fit without compromising accuracy. We also discussed the pros and cons of some modern techniques to compress deep-learning models. Finally, we touched on the idea that each of the model compression techniques mentioned can either be applied individually or can be combined.
Be sure to explore all the techniques for your model, post-training as well as during training, and figure out what works best for you.
About the Author
