
This article explores the limiting factors to running deep learning computer vision at the edge.
Autonomous driving, facial recognition, traffic surveillance, person tracking, and object counting, all these applications have one thing in common, computer vision (CV).
Since AlexNet, a deep learning algorithm won the ImageNet Large Scale Visual Recognition Challenge (ILSVRC) CV Competition in 2012, more applications are taking advantage of this advancement in CV.
While the deep learning models are getting better and better at CV tasks such as object detection, these models are getting bigger and bigger. From 2012 to 2015, the size of the winning model in the ILSVRC CV increased 16 times.
The bigger the model, the more the parameters it has, and the higher the numbers of computations it needs for inference, which in turn means higher energy consumption.
It took AlphaGo, an AI, 1,920 CPUs, and 280 GPUs to train in order to beat the human champion in the game Go, which is approximately $3,000 in electricity costs. Deep learning models are no doubt improving and have outperformed humans in certain tasks, but pay the cost in terms of an increase in size and higher energy consumption.
Researchers have access to GPU-powered devices to run their experiments on and so most of the baseline models are trained and evaluated on GPU devices. It is great if we just want to keep improving these models, but poses a challenge when we want to use it for real-world applications to solve real-world problems.
From smartphones to smart homes, applications are now demanding real-time computation and real-time response. The major challenge is to meet this real-time demand by running deep learning computer vision in a computationally limited platform.
The real achievement is when we can use this on a $5 device, such as a Raspberry Pi Zero in real-time, without compromising on accuracy.
What is Being Done to Improve Deep Learning Computer Vision?
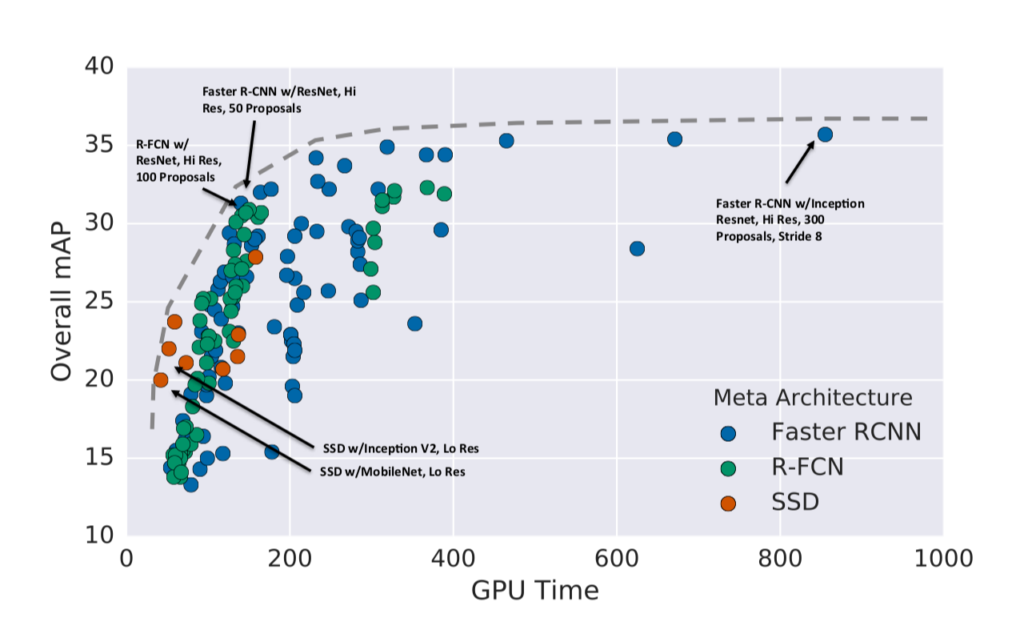
Previous models such as YOLO and R-CNN have proved their efficiency and accuracy in GPU based computers but are not useful for real-time application that uses non-GPU computers.
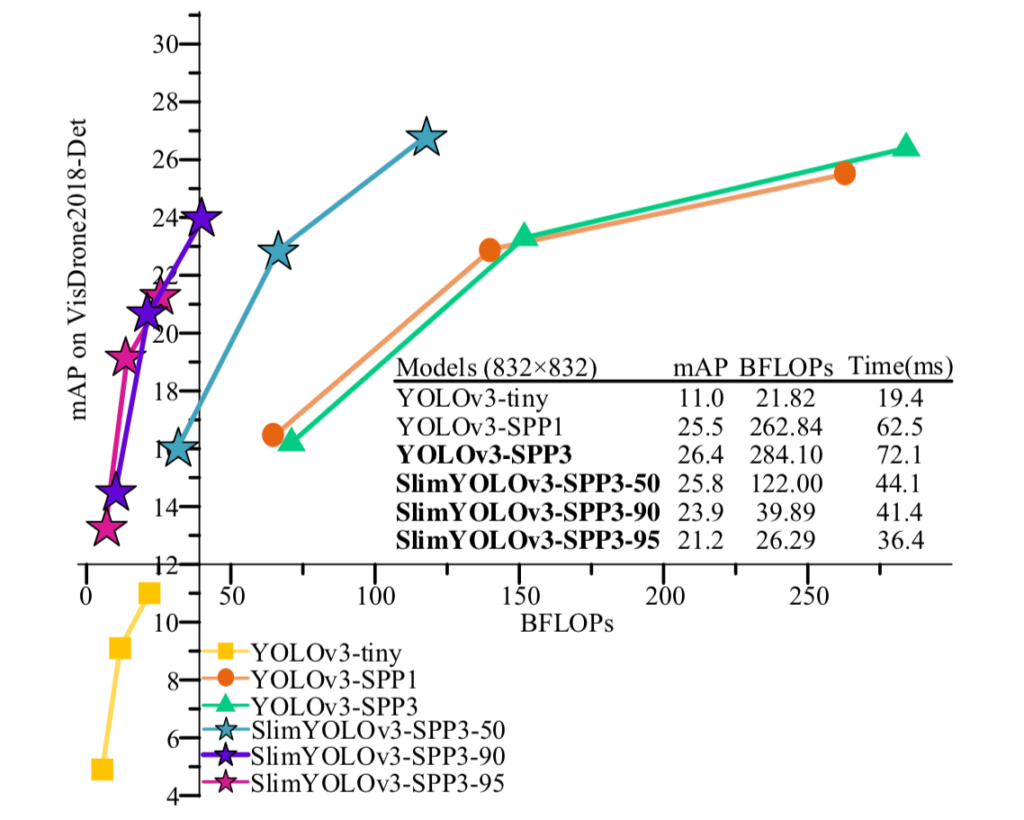
Over the years, variations of these models have been developed to meet the real-time requirements, and while they are successful in shrinking down the model in size so that they fit and run on computationally limited Edge AI devices utilizing very low memory, they compromise on accuracy. MobileNets, SqueezeNet, TinyYOLO, YOLO-LITE, and SlimYOLO are some examples of these models.
There is a tradeoff between system matrices when making deep neural network (DNN) design decisions. A DNN model with higher accuracy, for example, is more likely to use more memory to store model parameters and have higher latency. On the contrary, a DNN model with fewer parameters is likely to use less computational resources and thus execute faster, but may not have the accuracy required to meet the applications’s requirements.
Drones or general unmanned aerial vehicles (UAVs), with vehicle tracking capability, for example, need to be energy efficient so that they can operate for a longer time on battery power, and track a vehicle in real-time with high accuracy. Otherwise, it will be of less value.
Think about how annoying it is when you open the camera application of your smartphone and everyone is ready with their pose, and it takes forever for the camera to open, and again when it opens, it takes forever to click a single photo. If we expect the camera in our smartphones to be fast, it is reasonable to expect high performance from vehicle tracking drones.
To meet the real-time demands, deep learning models need to have low latency for faster response, be small so that they can be put into Edge AI devices, utilise minimum energy so that they can run on battery for a longer period of time, and have the same accuracy as when they run on GPU powered devices.
Xailient’s Detectum is the solution!
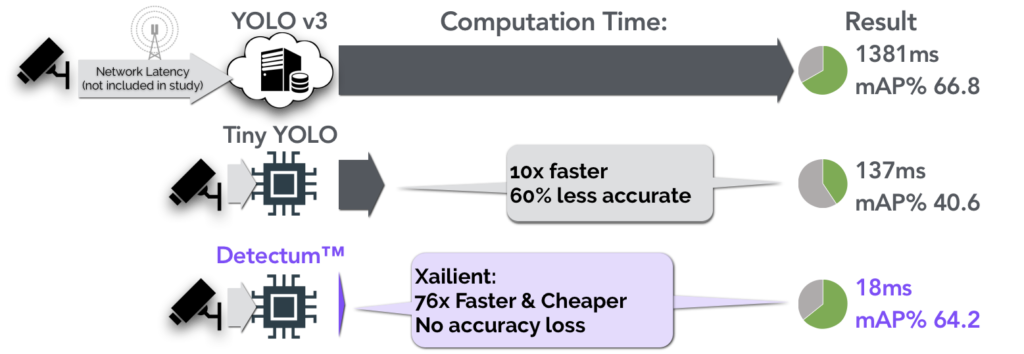
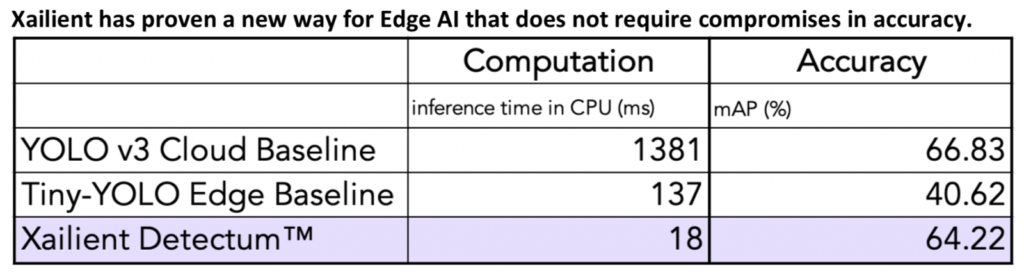
Xailient has proven that Detectum software performs CV 98.7% more efficiently without losing accuracy. Detectum object detection, which performs both localization and classification of objects in images and video, has been demonstrated to outperform the industry-leading YOLOv3.
Xailient achieved the same accuracy 76x faster than the cloud baseline and was 8x faster than the edge baseline without the accuracy penalty.
The development of deep learning computer vision is advancing at a rapid pace, and while they are getting better in accuracy, industry efforts are increasing in size, thus impacting computational time and cost.
While research is being done to reduce the size of the deep learning models so that they can run on low-power Edge AI devices, there is a trade-off between speed, accuracy, size, and energy consumption. Xailient’s Detectum is the answer to this challenge, as it has proven to run 76 times faster than YOLOv3 and 8 times faster than the TinyYOLO, achieving the same accuracy.
About the Author
