
Overview
Edge computing and fog computing can be defined as computing methods that bring compute and data processing closer to the site where data is initially generated and collected. This article explains Edge and fog computing in detail, highlighting the similarities and important differences between these two computing methods.
What is Fog Computing?
The term fog computing, originally coined by the company Cisco, refers to an alternative to cloud computing. A fog computing approach acts upon a dual problem. That is, the proliferation of computing devices and the opportunity presented by the data those devices generate (by locating certain resources and transactions closer to the edge of a network).
Fog computing is the zone located between the cloud and the Edge. The word ‘fog’ in fog computing is a metaphor since fog is defined as clouds close to the ground. This relates to how fog computing is located below the cloud and just above the Edge of the network.
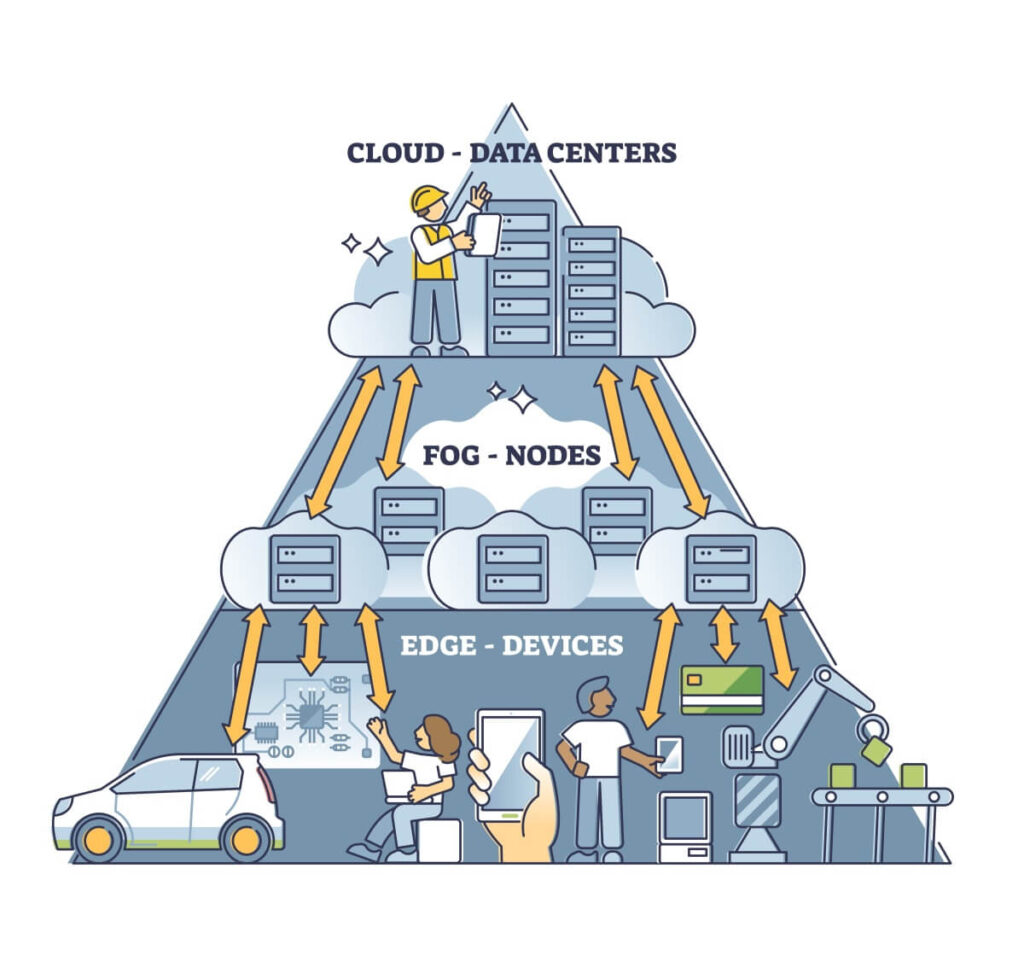
But what is the Edge?
Edge computing is a modern computing paradigm that functions at the edge of the network. It allows client data to be processed closer to the data source instead of far-off centralized locations such as huge cloud data centers.
Simply put, Edge computing takes data storage, enterprise applications, and computing resources closer to where the user physically consumes the information.
By moving applications to the Edge, the processing time is cut since Edge computing eliminates the need to wait for data to get back from a centralized processing system. Consequently, efficiency is increased, and the necessity for internet bandwidth is decreased.
This localized aspect of Edge computing also reduces operating costs and allows Edge-powered technologies to function in remote locations with intermittent connectivity.
On top of all this, Edge computing offers excellent security. This is because it allows data to stay on-device, requiring less contact with public cloud networks and platforms.
Now that we’ve covered the Edge, let’s turn our attention back to fog computing.
Since fog computing is between the Edge and the cloud, it can take data from the Edge before it reaches the cloud. The data taken in at the fog is then classified as to what is relevant and what is not.
After this, the relevant data remains in the cloud for storage, and the rest of the unimportant data gets deleted or remains in a fog node for remote access.
When a fog zone is in place, data sent from the Edge reaches a fog node through a localized network instead of going straight to the cloud. The data is then assessed based on a set of pre-existing parameters.
This assessment determines whether or not the data is important enough to send to the cloud. By filtering out irrelevant data, traffic is lessened, bandwidth improves, and latency is reduced.
An excellent example of fog computing is an embedded application on a production line. Here, a temperature sensor connected to the Edge measures temperature by the second. If these measurements are sent to the cloud every second (24 hours a day, 7 days a week), the data will pile up to a massive amount.
With fog computing, irrelevant measurements would get filtered out and deleted.
Edge Computing VS Fog Computing
Although Edge and fog computing share some commonalities, they are still very different computing methods.
Let’s explore their similarities and differences.
The similarities between Edge and fog computing
Both Edge computing and fog computing are viable solutions to combat the tremendous amounts of data gathered through IoT devices worldwide.
Both technologies keep data closer to where it originated and perform computations usually done in the cloud. This means that both Edge and fog computing can rely less on cloud-based platforms for data analysis, which, in turn, minimizes latency.
Additionally, Edge and fog computing offer increased security and privacy by encrypting data. They can also identify potential cyber-attacks and put security measures into place quickly.
Each of these computing methods can enable autonomous operations. Even in locations where connectivity is intermittent, or bandwidth is limited, these two technologies can still process data locally.
This is highly beneficial in remote use cases where internet connections are out of range.
Edge and fog computing offers better bandwidth efficiency than cloud computing because they process data outside the cloud, resulting in minimal bandwidth and expenses.
Savings in terms of bandwidth is something to note, especially when there is a slew of devices in IoT environments.
The differences between Edge and Fog computing
One of the significant differences between Edge and fog computing is where computation and data analysis occur.
Fog computing takes place further away (in physical distance) from sensors that generate data. On the other hand, Edge computing takes place right on the devices attached to the sensors, or in some cases, on a gateway device that is physically close to sensors.
Data is analyzed within an IoT gateway when fog computing is used. With Edge computing, data is analyzed on the sensor itself or the actual device.
In essence, when Edge computing is employed, data is not transferred anywhere. This cuts costs and allows data to be analyzed in real-time, optimizing performance. Additionally, since the data doesn’t need to be transferred, it is more secure and contained on the original device that generated it.
Regarding the scope of the two methods, it should be noted that Edge computing can handle data processing for business applications and send results straight to the cloud. Therefore, Edge computing can be done without the presence of fog computing.
In contrast, Fog computing can’t exist without Edge computing because it can’t produce data alone. It works by cutting down the work of both the Edge and the cloud, taking on specific processing tasks from the two.
As far as the applications for these two methods go, Edge computing is utilized mainly for more minor resource-intensive applications because devices have limited capabilities in terms of data collection. Healthcare applications in the form of patient monitoring, predictive maintenance in the form of sensors, and large-scale multiplayer gaming are applications that bring Edge computing into play.
On the other hand, fog computing is primarily used for applications that process large volumes of data gathered across a network of devices. It’s ideal for use cases like smart grids and autonomous vehicles.
As for storage and processing, Edge computing stores and processes data inside the device itself or at a point extremely close to it. Fog computing functions more as a gateway since fog computing connects to numerous Edge computing systems to store and process data.
When considering the costs of the two computing methods, Edge computing services have more of a standard recurring fee based on how they are used and configured.
Fog computing services are more customizable and require greater set-up costs. This, of course, means that fog computing comes at a higher price compared to Edge computing.
Edge or fog – Which computing method is best?
Edge and fog computing are technological structures with modern applications that are rapidly gaining popularity. Both take computing abilities closer to the data source, taking the pressure off centralized cloud data centers.
If it is a question of costs, Edge computing (unless customized) is the less expensive alternative since established vendors provide the service at a fixed price.
Start-up costs for fog computing mean additional expenses on the hardware front since fog computing needs to utilize both the Edge and the cloud.
Edge computing can process data for business applications and transmit the results of these processes to the cloud, making Edge computing possible without fog computing. On the other hand, Fog computing cannot produce data, making it inoperative without Edge computing.
The main advantages of both these computing methods are improved user experience, systematic data transfer, and minimal latency.
About the Author
